安装
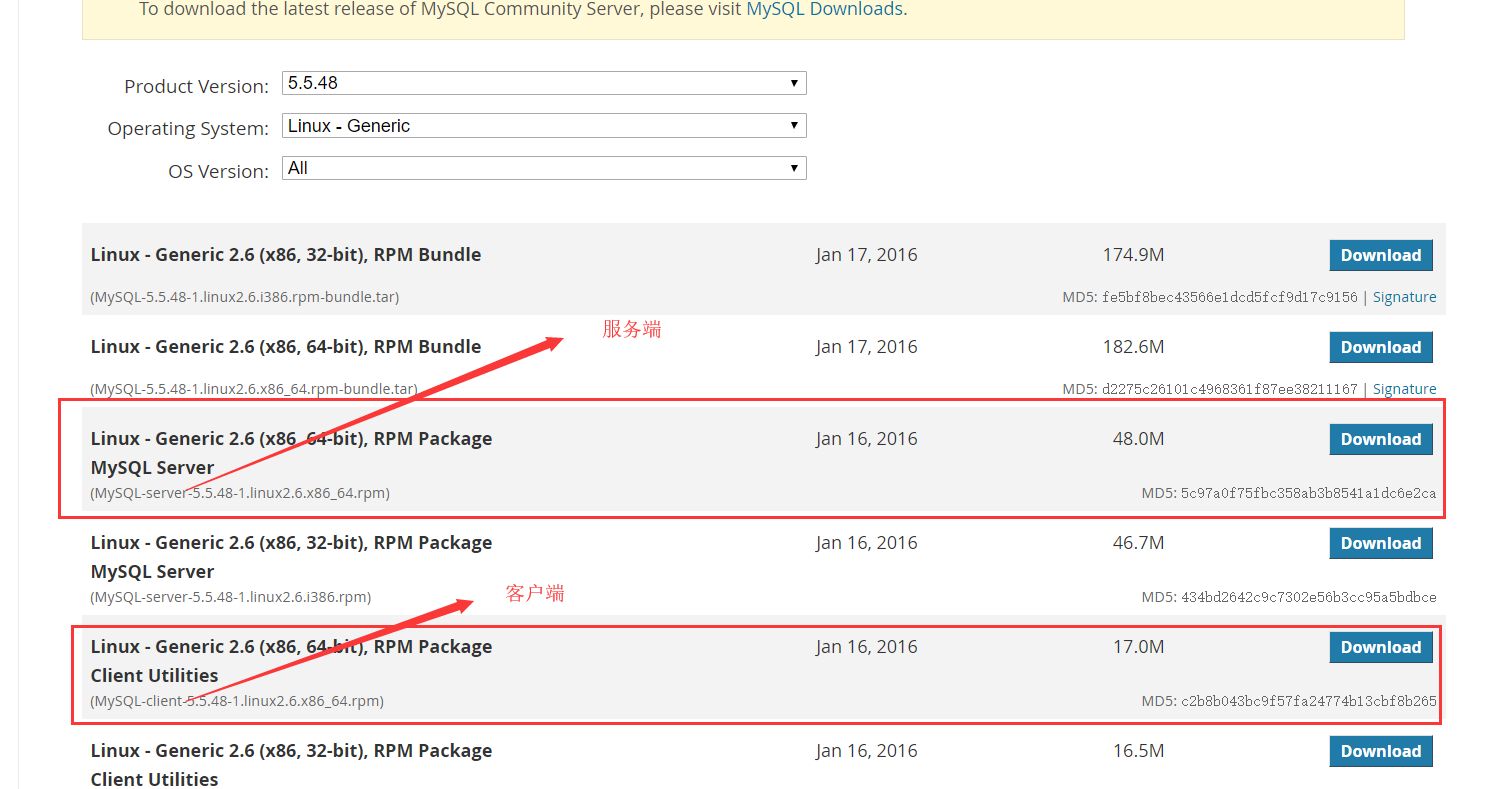
下载
MySQL :: Download MySQL Community Server (Archived Versions)
rzsz
1 | [root@192 modules]# yum -y install lrzsz |
上传
1 | [root@192 modules]# ll |
卸载
方式一
1 | [root@192 modules]# rpm -qa | grep -i mysql |
方式二
1 | [root@192 modules]# yum -y remove mysql-libs-5.1.73-7.el6.x86_64 |
如果提示“GPG keys...”安装失败,解决方案:rpm -ivh rpm软件名 --force --nodoeps
服务端
1 | [root@192 modules]# rpm -ivh MySQL-server-5.5.48-1.linux2.6.x86_64.rpm |
客户端
1 | [root@192 modules]# rpm -ivh MySQL-client-5.5.48-1.linux2.6.x86_64.rpm |
验证
1 | [root@192 mysql]# mysqladmin --version |
启动服务
方式一
1 | [root@192 mysql]# service mysql start; |
方式二
- 在计算机
reboot后 登陆MySQL:mysql可能会报错:"/var/lib/mysql/mysql.sock不存在"- 原因:是
Mysql服务没有启动 - 解决 : 启动服务
- 每次使用前 手动启动服务
/etc/init.d/mysql start - 开机自启
chkconfig mysql on,chkconfig mysql off
- 每次使用前 手动启动服务
- 原因:是
1 | [root@192 modules]# /etc/init.d/mysql start |
方式三
- 开启自启
mysql服务
1 | [root@192 mysql]# chkconfig mysql on |
关闭服务
1 | [root@192 mysql]# service mysql stop |
重启服务
1 | [root@192 mysql]# service mysql restart; |
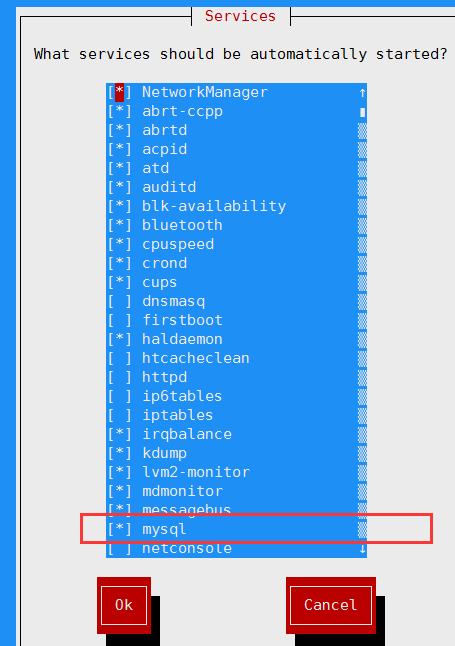
检查开机是否自动启动mysql服务
1 | [root@192 mysql]# ntsysv |
修改密码
1 | [root@192 modules]# /usr/bin/mysqladmin -u root password '000000' |
连接
1 | [root@192 modules]# mysql -uroot -p |
授权
1 | mysql> grant all privileges on *.* to root@'%' identified by "000000"; |
坑
客户端连接不上
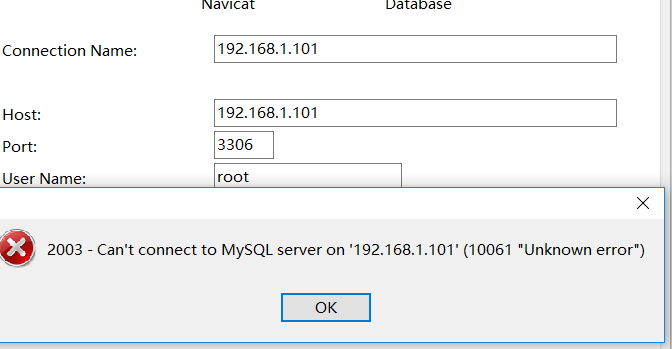
关闭防火墙
1
2
3
4
5
6[root@192 ~]# service iptables stop;
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@192 ~]# service iptables status;
iptables: Firewall is not running.
rpm安装mysql,找不到/etc/my.cnf- 复制
/usr/share/mysql目录下的my-huge.cnf文件到/etc目录,并改名为my.cnf即可
- 复制
1 | [root@192 mysql]# cp /usr/share/mysql/my-huge.cnf /etc/my.cnf |
数据库存放目录
1 | [root@192 mysql]# ps -ef|grep mysql |
- 数据库目录
datadir=/var/lib/mysql pid文件目录:--pid-file=/var/lib/mysql/bigdata01.pid
MySQL核心目录
- /var/lib/mysql :mysql 安装目录
- /usr/share/mysql: 配置文件
- /usr/bin:命令目录(mysqladmin、mysqldump等)
- /etc/init.d/mysql启停脚本
MySQL配置文件
- my-huge.cnf 高端服务器 1-2G内存
- my-large.cnf 中等规模
- my-medium.cnf 一般
- my-small.cnf 较小
但是,以上配置文件mysql默认不能识别,默认只能识别/etc/my.cnf,因此需要拷贝一份以上配置文件
1 | [root@192 mysql]# cp /usr/share/mysql/my-huge.cnf /etc/my.cnf |
注意:mysql5.5默认配置文件/etc/my.cnf;Mysql5.6默认配置文件/etc/mysql-default.cnf
mysql字符编码
查看字符编码
1 | mysql> show variables like '%char%'; |
安装NPPFTP
设置—导入—-导入插件
修改字符编码为utf8
编辑配置文件vim /etc/my.cnf,追加
1 | [mysql] |
再次查看字符编码
1 | mysql> show variables like '%char%'; |
清屏
- Ctrl+L
- system clear
SQL语句查询
步步深入:MySQL架构总览->查询执行流程->SQL解析顺序 - AnnsShadoW - 博客园
语法顺序
- SELECT
- FROM
- LEFT JOIN
- ON
- WHERE
- GROUP BY
- HAVING
- ORDER BY
- LIMIT
执行顺序
1 | SELECT * FROM user LEFT JOIN order ON user.id = order.uid WHERE order.price > 1000 GROUP BY user.name HAVING count(1) > 5 ORDER BY user.name LIMIT 0,10 |
- FROM(将最近的两张表,进行笛卡尔积),得到临时结果集VT1
- ON(将VT1按照它的条件进行过滤)—VT2
- LEFT JOIN(保留左表的记录)—VT3
- WHERE(过滤VT3中的记录)–VT4…VTn
- GROUP BY(对VT4的记录进行分组)—VT5
- HAVING(对VT5中的记录进行过滤)—VT6
- SELECT(对VT6中的记录,选取指定的列)–VT7
- ORDER BY(对VT7的记录进行排序)–游标
- LIMIT(对排序之后的值进行分页)
WHERE条件执行顺序(影响性能)
- MYSQL:从左往右去执行WHERE条件的。
- Oracle:从右往左去执行WHERE条件的。
结论:写WHERE条件的时候,优先级高的部分要去编写过滤力度最大的条件语句。

多表之间关系
一对一
一对多
从表是:分类表。从表中,应该有一个字段去关联主表,而这个关联字段就是主键。
主表是:商品表。主表中,应该有一个字段去关联从表,而这个关联字段就是外键。

在互联网项目中,一般情况下,不建议建立外键关系。
多对多
- 双向的一对多
存储引擎
- 存储引擎是针对表的,MySQL 5.5之后,默认的存储引擎由MyISAM变为InnoDB。
查询数据库支持哪些引擎
1 |
|
查看当前使用的引擎
1 | mysql> show variables like '%storage_engine%' ; |
指定数据库对象的引擎
1 | create table tb( |
日志文件、数据文件
日志位置
1 | mysql> SHOW GLOBAL VARIABLES LIKE '%log%'; |
二进制日志
- 记录了数据库所有的ddl语句和dml语句,但不包括select语句内容
- 用于恢复数据
1 | mysql> SHOW VARIABLES LIKE 'log_bin%'; |
错误日志
1 | mysql> SHOW VARIABLES LIKE 'log_error%'; |
查询日志
1 | mysql> SHOW VARIABLES LIKE 'general_log%'; |
慢查询日志
1 | mysql> SHOW VARIABLES LIKE 'slow_query_log%'; |
数据位置
1 | mysql> SHOW VARIABLES LIKE '%datadir%'; |
SQL优化
MySQL :: MySQL 5.5 Reference Manual :: 8 Optimization
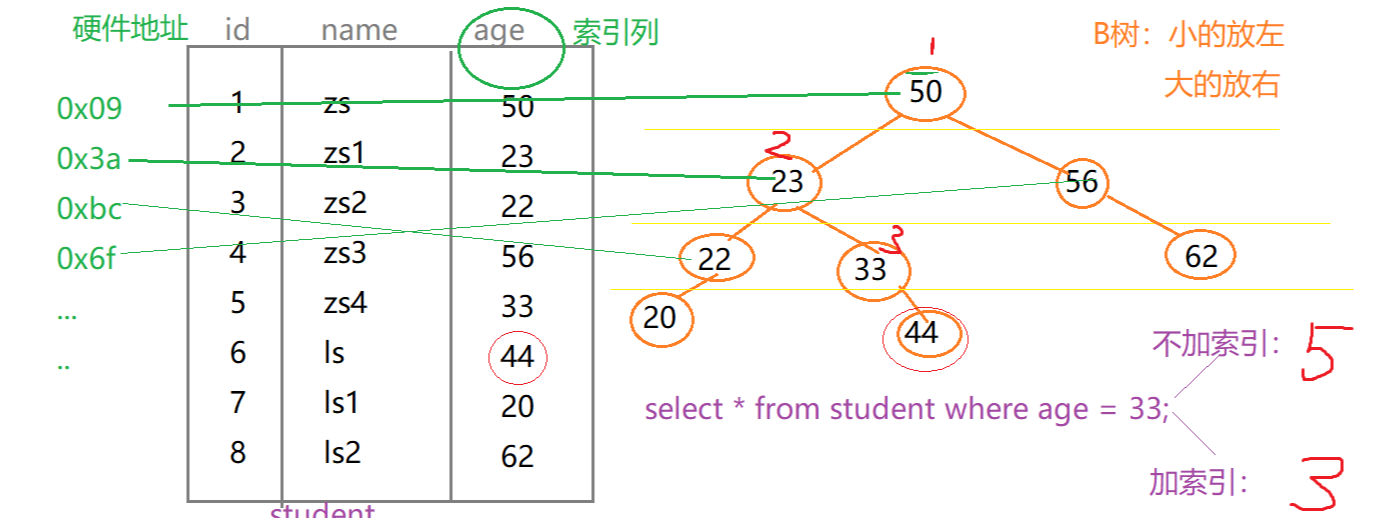
SQL优化, 主要就是 在优化索引,索引就 相当于书的目录
索引(index)是帮助MYSQL高效获取数据的数据结构。索引是数据结构(树:B树(默认)、Hash树…)
B树索引
select * from student where age = 33如果不加索引,从上往下查找需要查找5次,而加了索引,查找的节点处于第三层,所以只需要查找3次
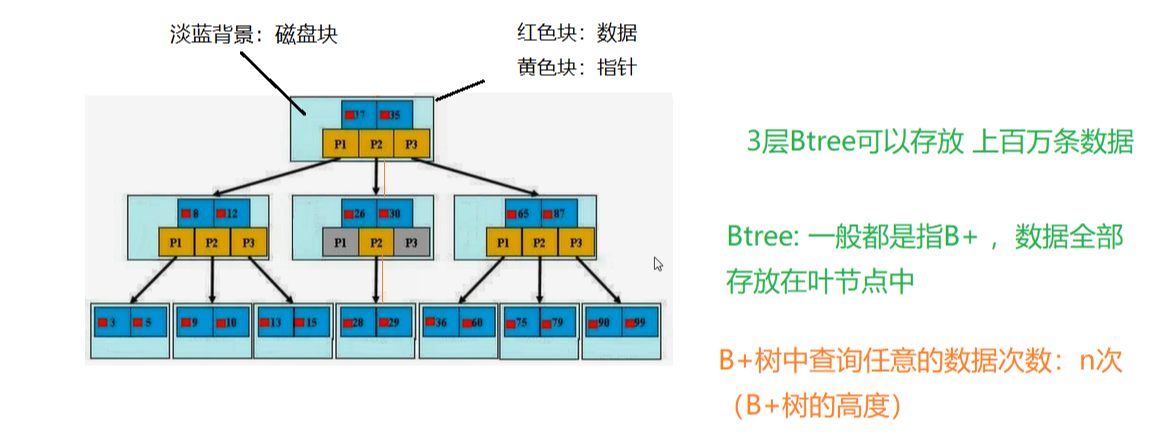
B+Tree
Btree数据全部放在叶子节点
分类
- 主键索引: 不能重复,是一种特殊的唯一索引,不允许有空值
- 唯一索引 :不能重复,允许为空值
- 单值索引 : 单列, age ;一个表可以多个单值索引,name。
- 组合索引 :多个列构成的索引 ,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀集合。
创建索引
如果一个字段是主键primary key,则该字段默认就是主键索引,需要注意的是DDL语句会自动提交,我们不需要手动commit
方式一
create 索引类型 索引名 on 表(字段)
- 单值索引
1 | create index dept_index on tb(dept); |
- 唯一索引
1 | create unique index name_index on tb(name) ; |
- 组合索引
1 | create index dept_name_index on tb(dept,name); |
方式二
alter table 表名 索引类型 索引名(字段)
- 单值索引
1 | alter table tb add index dept_index(dept) ; |
- 唯一索引
1 | alter table tb add unique index name_index(name); |
- 组合索引
1 | alter table tb add index dept_name_index(dept,name); |
删除索引
drop index 索引名 on 表名 ;
1 | drop index name_index on tb ; |
查询索引
show index from 表名 ;show index from 表名 \G
1 | mysql> show index from tb; |
优势
- 提高查询效率(降低IO使用率)
- 降低CPU使用率 (
...order by age desc,因为 B树索引 本身就是一个 好排序的结构,因此在排序时 可以直接使用)
弊端
- 索引本身很大, 可以存放在内存/硬盘(通常为 硬盘)
- 索引不是所有情况均适用
- 少量数据
- 频繁更新的字段
- 很少使用的字段
- 索引会降低增删改的效率(增删改 查)
建议
- 尽量创建组合索引(组合索引其实会默认按照最左前缀原则帮我们创建多组索引)
- 组合索引(id,name,sex)会帮我们创建多组索引—–>[id],[id,name],[id,sex],[id,name,sex],[name,sex]
SQL故障排除
- 慢查询日志:MySQL提供的一种日志记录,用于记录MySQL种响应时间超过阀值的SQL语句 (long_query_time,默认10秒)
- 慢查询日志默认是关闭的;建议一般开发调优时是打开,而最终部署时关闭。
- 性能优化思路
- 首先需要使用慢查询功能,去获取所有查询时间比较长的SQL语句
- 其次使用explain命令去查看有问题的SQL的执行计划
- 最后可以使用show profile[s] 查看有问题的SQL的性能使用情况
查看慢查询
临时开启
方式一
1 | mysql> show variables like '%slow_query_log%' ; |
方式二
1 | mysql> show variables like '%slow_query_log%' ; |
永久开启
编辑/etc/my.cnf 中追加配置:
1 | vi /etc/my.cnf |
查看慢查询阀值
1 | mysql> show variables like '%long_query_time%' ; |
临时设置阀值
- 设置完毕后,重新登陆后起效 (不需要重启服务)
1 | mysql> show variables like '%long_query_time%' ; |
永久设置阀值
编辑/etc/my.cnf中追加配置:
1 | vi /etc/my.cnf |
查看SQL执行计划
explain +SQL语句
1 | mysql> explain select * from tb ; |
- id : 编号
- select_type :查询类型
- table :表
- type :类型
- possible_keys :预测用到的索引
- key :实际使用的索引
- key_len :实际使用索引的长度
- ref :表之间的引用
- rows :通过索引查询到的数据量
- Extra :额外的信息
表结构
- 课程表
(course) - 教师表
(teacher) - 教师课程描述表
(teacherCard)
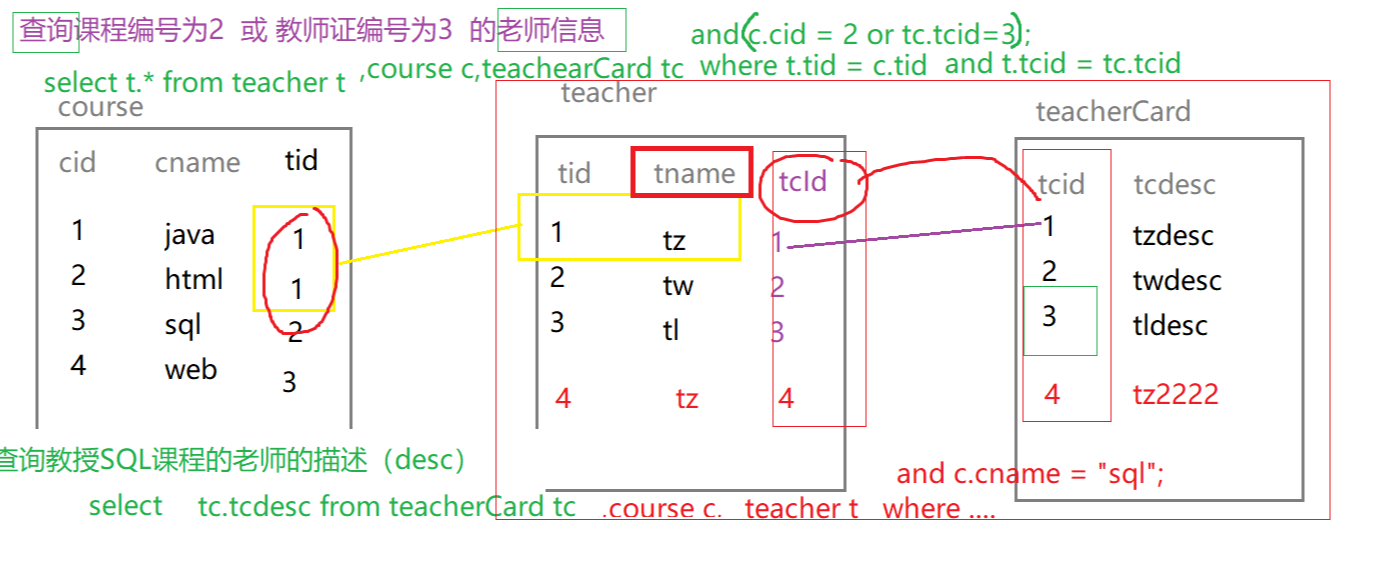
准备数据
1 | create table course |
id
id值相同
id值相同,从上往下 顺序执行。数据小的表优先查询
用
wehre连接表之间的关系,表的执行顺序是因数量的个数改变而改变,当教师表新插入3条数据,教师表变成了最后执行的原因是遵循笛卡儿积,尽管3*4*6=72和6*4*3=72最终的条数是一样的,但是它们的中间结果是不一样的,查询3*4=12条效率明显比6*4=24高
查询课程编号为2或教师证编号为3的老师信息
1 |
|
id值不同
id值越大越优先查询 (本质上在嵌套子查询时,先查内层 再查外层)
查询教授SQL课程的老师的描述(desc)
1 | mysql> explain select tc.tcdesc from teacherCard tc,course c,teacher t where c.tid = t.tid |
id值有相同,又有不同
- id值越大越优先;id值相同,从上往下 顺序执行
子查询+多表
1 | mysql> explain select t.tname ,tc.tcdesc from teacher t,teacherCard tc where t.tcid= tc.tcid |
select_type
查询类型
PRIMARY:包含子查询SQL中的 主查询 (最外层)
SUBQUERY:包含子查询SQL中的 子查询 (非最外层)
simple:简单查询(不包含子查询、union)
derived:衍生查询(使用到了临时表)
在from子查询中只有一张表
1
2
3
4
5
6
7
8mysql> explain select cr.cname from ( select * from course where tid in (1,2) ) cr ;
+----+-------------+------------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+------+---------------+------+---------+------+------+-------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 3 | |
| 2 | DERIVED | course | ALL | NULL | NULL | NULL | NULL | 4 | Using where |
+----+-------------+------------+------+---------------+------+---------+------+------+-------------+
2 rows in set (0.00 sec)
在from子查询中, 如果有table1 union table2 ,则table1 就是derived,table2就是union
1
2
3
4
5
6
7
8
9
10mysql> explain select cr.cname from ( select * from course where tid = 1 union select * from course where tid = 2 ) cr ;
+----+--------------+------------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+------------+------+---------------+------+---------+------+------+-------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 3 | |
| 2 | DERIVED | course | ALL | NULL | NULL | NULL | NULL | 4 | Using where |
| 3 | UNION | course | ALL | NULL | NULL | NULL | NULL | 4 | Using where |
| NULL | UNION RESULT | <union2,3> | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------+------------+------+---------------+------+---------+------+------+-------------+
4 rows in set (0.00 sec)
union:上例
union result :告知开发人员,那些表之间存在union查询
type
索引类型、类型
- 对type进行优化的前提:有索引
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
比较常见的system>const>eq_ref>ref>range>index>all,其中system,const只是理想情况;实际能达到 的是ref>range
system
可以忽略: 只有一条数据的系统表 ;或 衍生表只有一条数据的主查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40mysql> create table test01
-> (
-> tid int(3),
-> tname varchar(20)
-> );
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> insert into test01 values(1,'a') ;
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> show tables;
+---------------+
| Tables_in_kkb |
+---------------+
| course |
| lock |
| tb |
| teacher |
| teacherCard |
| test01 |
| user |
+---------------+
7 rows in set (0.00 sec)
mysql> alter table test01 add constraint tid_pk primary key(tid) ;
Query OK, 1 row affected (0.02 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> explain select * from (select * from test01 )t where tid =1 ;
+----+-------------+------------+--------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+------+---------+------+------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | |
| 2 | DERIVED | test01 | ALL | NULL | NULL | NULL | NULL | 1 | |
+----+-------------+------------+--------+---------------+------+---------+------+------+-------+
2 rows in set (0.00 sec)const
仅仅能查到一条数据的
SQL,用于Primary key或unique索引 (类型 与索引类型有关)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
mysql> explain select tid from test01 where tid =1 ;
+----+-------------+--------+-------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+-------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | test01 | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index |
+----+-------------+--------+-------+---------------+---------+---------+-------+------+-------------+
1 row in set (0.00 sec)
mysql> alter table test01 drop primary key ;
Query OK, 1 row affected (0.02 sec)
Records: 1 Duplicates: 0 Warnings: 0
mysql> explain select tid from test01 where tid =1 ;
+----+-------------+--------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | test01 | ALL | NULL | NULL | NULL | NULL | 1 | Using where |
+----+-------------+--------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> create index test01_index on test01(tid) ;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select tid from test01 where tid =1 ;
+----+-------------+--------+------+---------------+--------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+--------------+---------+-------+------+-------------+
| 1 | SIMPLE | test01 | ref | test01_index | test01_index | 4 | const | 1 | Using index |
+----+-------------+--------+------+---------------+--------------+---------+-------+------+-------------+
1 row in set (0.00 sec)
1 |
|
以上SQL,用到的索引是 t.tcid,即teacher表中的tcid字段;
如果teacher表的数据个数 和 连接查询的数据个数一致(都是3条数据),则有可能满足eq_ref级别;否则无法满足。
ref
非唯一性索引,对于每个索引键的查询,返回匹配的所有行(0行或者多行)
1 | mysql> insert into teacher values(4,'tz',4) ; |
range
检索指定范围的行 ,where后面是一个范围查询
- between
- < >=
- 特殊的情况,
in有时候会失效 ,从而转为 无索引,进行全表扫描all)
1 | mysql> alter table teacher add index tid_index (tid) ; |
index
查询全部索引中数据,tid 是索引, 只需要扫描索引表,不需要所有表中的所有数据
1 | mysql> show index from teacher; |
all
查询全部表中的数据
1 | mysql> show index from course; |
possible_keys
可能用到的索引,是一种预测,不准
1 | mysql> alter table course add index cname_index (cname); |
如果 possible_key/key是NULL,则说明没用索引
1 | mysql> explain select tc.tcdesc from teacherCard tc,course c,teacher t where c.tid = t.tid |
key
实际使用到的索引
key_len
- utf8:1个字符3个字节
- gbk:1个字符2个字节
- latin:1个字符1个字节
索引的长度, 用于判断复合索引是否被完全使用,key_len为60,在utf8:1个字符占3个字节
1 | mysql> create table test_kl |
如果索引字段可以为Null,则会使用1个字节用于标识。因此key_len为61
1 | mysql> alter table test_kl add column name1 char(20) ; |
增加一个复合索引 ,根据最左前缀原则,两次key_len分别为121和60
1 | mysql> drop index index_name on test_kl ; |
索引字段为可变varchar类型,用2个字节 标识可变长度,1字节标识Null,因此20*3=60 + 1(null) +2(用2个字节 标识可变长度) =63
1 | mysql> alter table test_kl add column name2 varchar(20) ; |
ref
表之间的引用,注意与type中的ref值区分
指明当前表所参照的字段select ....where a.c = b.x ;(其中b.x可以是常量,const)
1 | mysql> desc course; |
rows
被索引优化查询的 数据个数 (实际通过索引而查询到的 数据个数)
1 | mysql> select * from course; |
Extra
using filesort
using filesort : 性能消耗大;需要“额外”的一次排序(查询) 。常见于 order by 语句中。
对于单索引, 如果排序和查找是同一个字段,则不会出现using filesort;如果排序和查找不是同一个字段,则会出现using filesort;,平常使用的话,where哪些字段,就order by那些字段
1 | mysql> create table test02 |
复合索引:不能跨列(最佳左前缀),where和order by按照复合索引的顺序使用,不要跨列或无序使用。
1 | mysql> drop index idx_a1 on test02; |
using temporary
using temporary:性能损耗大 ,用到了临时表。一般出现在group by 语句中。
查询那些列,就根据那些列 group by
1 | mysql> explain select a1 from test02 where a1 in ('1','2','3') group by a1 ; |
using index
性能提升; 索引覆盖(覆盖索引)。原因:不读取原文件,只从索引文件中获取数据 (不需要回表查询)
1 | mysql> show index from test02; |
如果用到了索引覆盖(using index时),会对possible_keys和key造成影响:
如果没有where,则索引只出现在key中;如果有where,则索引 出现在key和possible_keys中。
1 | mysql> explain select a1,a2 from test02 where a1='' or a2= '' ; |
查看SQL性能使用情况
1 | mysql> select @@profiling; |

