NodeJS入门
NodeJS模块
http模块
server.js
1 | const http=require('http'); |
server2.js
1 | const http=require('http'); |
断言——assert
1 | const assert=require('assert'); |
File System
读写文件
fs.js
1 | const fs=require('fs'); |
fs2.js
1 | const fs=require('fs'); |
多进程
进程和线程的区别:
进程拥有独立的执行空间、存储
同一个进程内的所有线程共享一套空间、代码
多进程(PHP、Node) 成本高(慢);安全(进程间隔离);进程间通信麻烦;写代码简单
多线程(Java、C) 成本低(快);不安全(线程要死一块死);线程间通信容易;写代码复杂
进程间通信的几种方式
管道
共享内存
socket
Crypto——签名
MD5是单向散列生成hash值,不可逆破解
md5.js
1 | const crypto=require('crypto'); |
双重加密
md5_2.js
1 | const crypto=require('crypto'); |
OS
获取系统信息
1 | const os=require('os'); |
Path
1 | const path=require('path'); |
Events事件队列
和普通js函数的定义调用区别:解耦
1 | const Event=require('events').EventEmitter; |
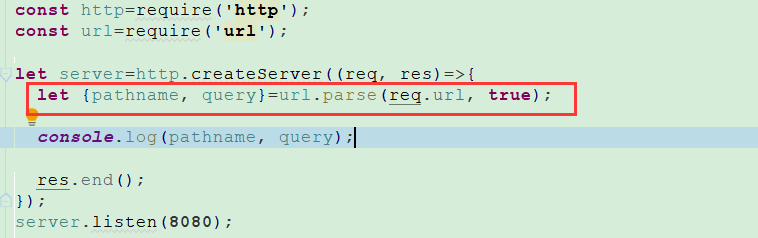
Query Strings、URL
地址解析
querystring.js
1 | const querystring=require('querystring'); |
url.js
1 | const url=require('url'); |
域名解析
DNS、Domain
1 | const dns=require('dns'); |
流操作——Stream
连续数据都是流——视频流、网络流、文件流、语音流
TLS/SSL
加密、安全
ZLIB——gz
压缩
NodeJS数据交互
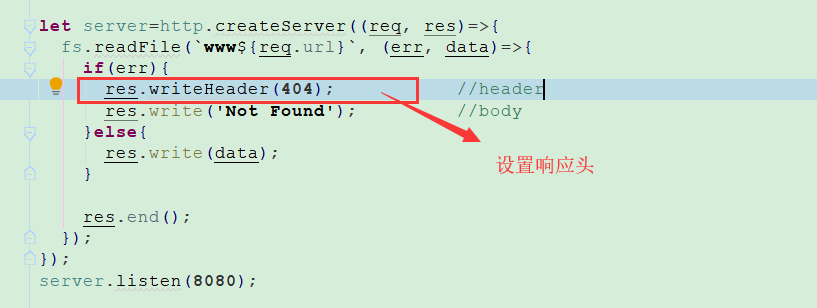
设置响应头
get请求
数据放在url地址上,存放的数量小(32k)
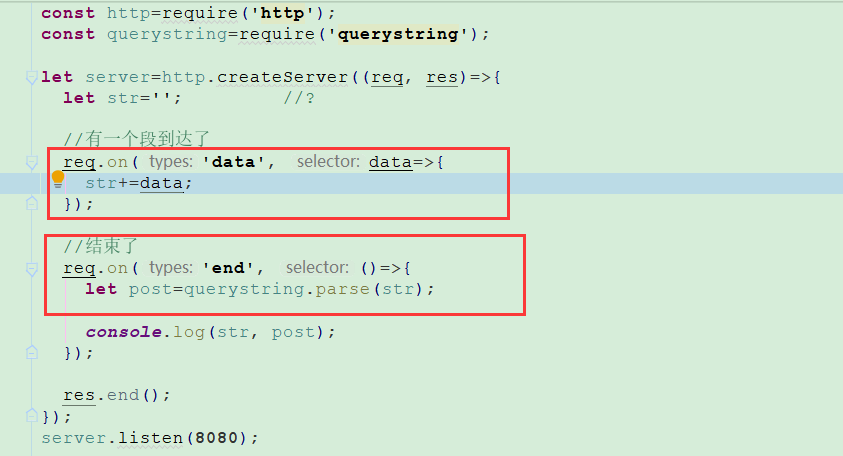
post请求
在body里面,存放的数据量大(1G),一个大数据包切成一堆小包传输,容错性强
安全性
一切来自前台的数据都不可信
前后台都得进行数据校验
前台校验:提高用户体验
后台校验:提高安全性
数据库
关系型数据库——MySQL、Oracle
特点
最常见、最常用,数据之间是有关系的
MySQL使用占比80%,免费,绝大多数普通应用,性能很高、安全性很高,容灾略差
Oracle收费,应用在金融、医疗,容灾特别强
SQL
增
INSERT INTO 表 (字段列表) VALUES(值列表)
1 | INSERT INTO user_table (ID, name, gender, chinese, math, english) VALUES(0, 'blue', '男', 35, 18, 29); |
删
DELETE FROM 表 WHERE 条件
1 |
|
改
UPDATE 表 SET 字段=值, 字段2=值2, … WHERE 条件
1 | UPDATE user_table SET chinese=100 WHERE ID=2; |
查
SELECT 字段列表 FROM 表 WHERE 条件
1 | SELECT name, gender FROM user_table WHERE ID=2; |
文件型数据库——sqlite
使用简单、存储数据量小
文档型数据库——MongoDB
直接存储异构数据,使用方便
NoSQL
没有复杂的关系、对性能有极高的要求常见的有redis、memcached、hypertable、bigtable
NodeJS进阶上
文件数据解析
表单的三种POST
text/plain,用的很少,纯文字application/x-www-form-urlencoded,默认,以url编码方式,xxx=xxx&xxx=xx...multipart/form-data上传文件内容

file上传,是post请求方式
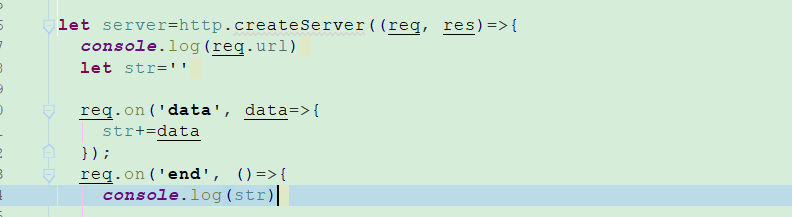
普通纯文本表单文件上传
普通纯文本文件上传可以用字符串拼接接收,有弊端,如果是图片文件上传,用字符串接收会出现数据错乱
描述:可以看到纯文本文件上传请求了2个资源
浏览器
后台结果输出
包含了前台表单用户名、密码和纯文本文件的描述和内容
1 | /upload |
Buffer接收文件上传的原始二进制数据
1 | /upload |
Buffer数据进行查找、截取、切分
如果是非纯文本文件上传,用字符串接收会破坏数据的完整性,需要用Buffer接收二进制数据
Buffer数据查找
1 | let b=new Buffer('abccc-=-dddder-=-qwerqwer'); |
Buffer数据截取
1 | let b=new Buffer('abccc-=-dddder-=-qwerqwer'); |
Buffer数据切分
Buffer本身不具有split方法
1 | let b=new Buffer('abccc-=-dddder-=-qwerqwer'); |
解析数据
数据化简
先对纯文本文件上传用字符串拼接的结果进行分析
化简版本一
1 | 分隔符 |
化简版本二:每一行末尾会自动加上\r\n
1 | 分隔符\r\n |
化简版本三
1 | 分隔符\r\n数据描述\r\n\r\n数据值\r\n |
化简到版本三的时候,就可以开始解析数据了
用分隔符切开数据
1 | [ |
丢弃头尾元素
1 | [ |
丢弃每一项的头尾
\r\n
1 | [ |
用第一次出现的
\r\n\r\n切分
普通数据:[数据描述, 数据值]
文件数据:[数据描述1\r\n数据描述2, <文件内容>]
判断描述的里面有没有
\r\n
有的话就是文件数据:[数据描述1\r\n数据描述2, <文件内容>]
没有的话就是普通数据:[数据描述, 数据值]
分析数据描述
文件上传代码实现
1 | const http=require('http'); |
流操作
fs.readFile和fs.writeFile的弊端
描述:以上文件上传的一个瑕疵就是会等到所有数据都到达了才开始处理,然后通过fs.writeFile上传文件
1 | http.createServer((req, res)=>{ |
fs.readFile先把所有数据全读到内存中,然后回调,这种方式极其占用内存且资源利用极其不充分,读取文件的过程中网络传输一直空闲,等到文件IO读取完毕,IO一直空闲,网络传输变得繁忙
解决:收到一部分就解析一部分,极大节约内存,使用流读取文件,读一点、发一点
分类
读取流fs.createReadStream
写入流fs.createWriteStream
1 | const http=require('http'); |
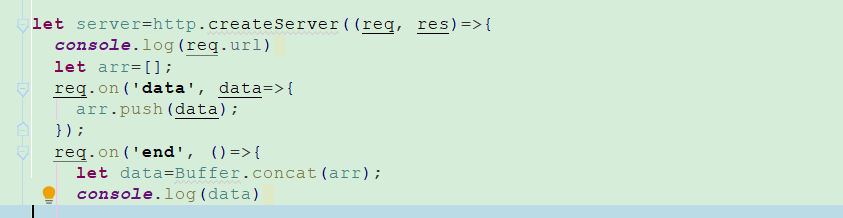
gz压缩
无gz压缩传输
没有通过gz压缩传输,请求资源1.html文件大小321B,jquery.js文件大小262KB
1 | const http=require('http'); |

gz压缩传输
读写流,通过gz压缩传输,请求资源1.html文件大小292B,jquery.js文件大小77.8KB
创建读取流读取www${req.url}文件,通过gz压缩、加密该文件然后返回给浏览器,需要设置响应头res.setHeader('content-encoding', 'gzip'),让浏览器识别该资源是通过gz压缩的文件
1 | const http=require('http'); |

NodeJS进阶下
缓存
标记文件修改时间实现缓存
获得文件修改时间
1 | const fs=require('fs'); |
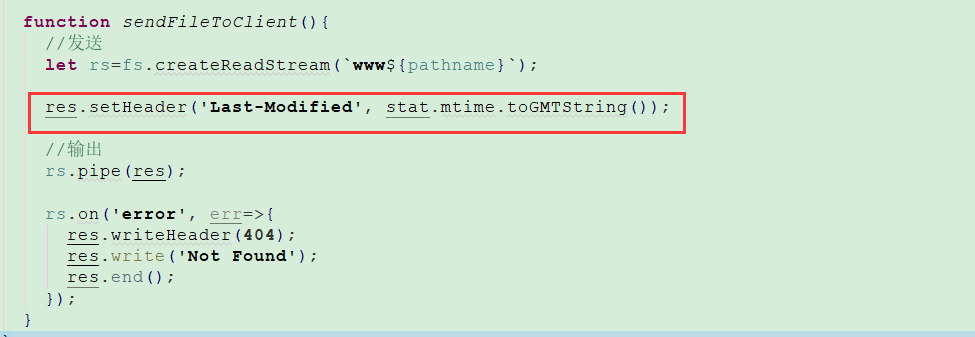
服务器设置响应头
Last-Modified
标记文件最后一次修改时间
缓存实现过程
1 | const http=require('http'); |
第一次请求,响应状态码200,浏览器没有缓存
服务器响应头带了Last-Modified标记该资源文件最后一次修改时间
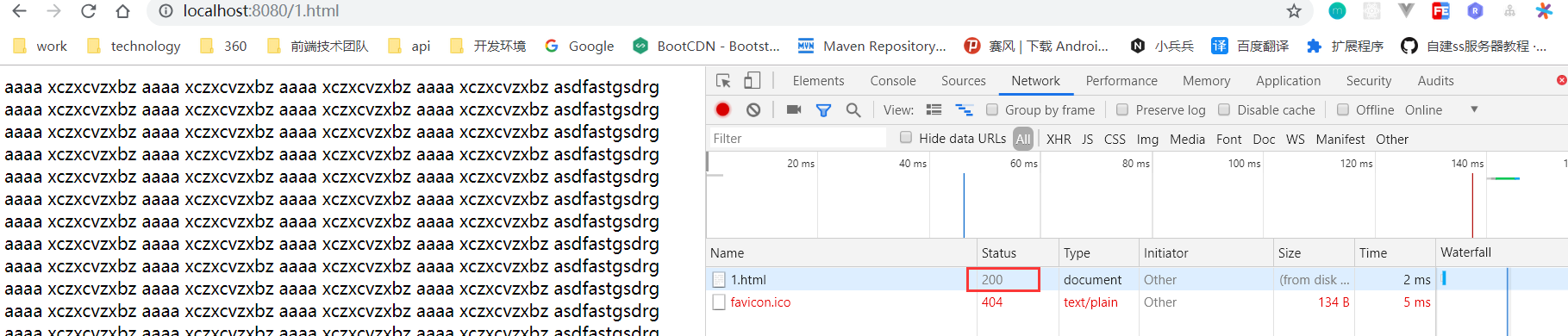
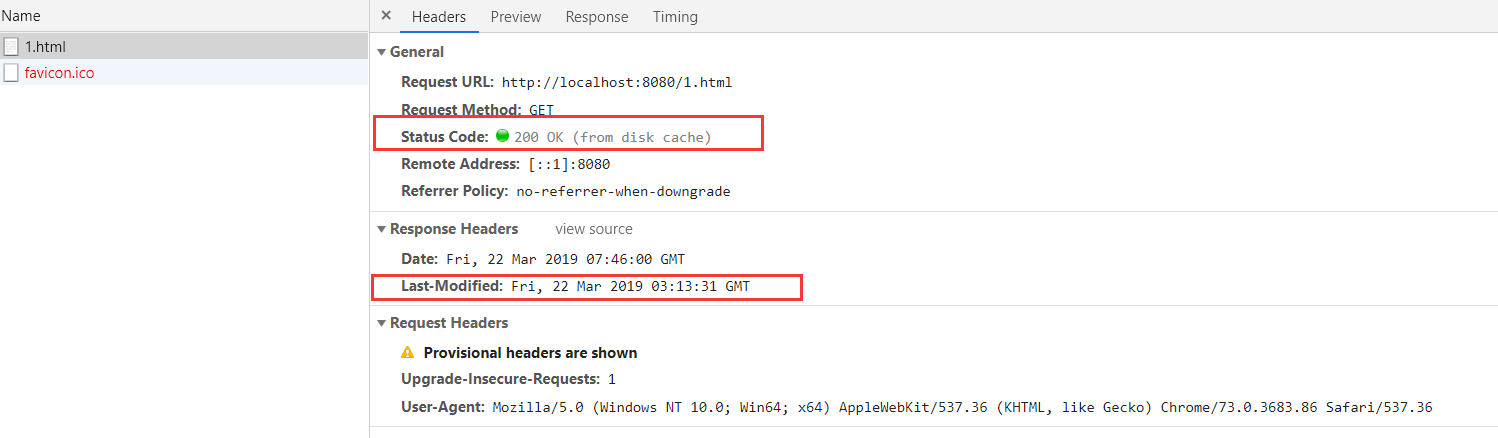
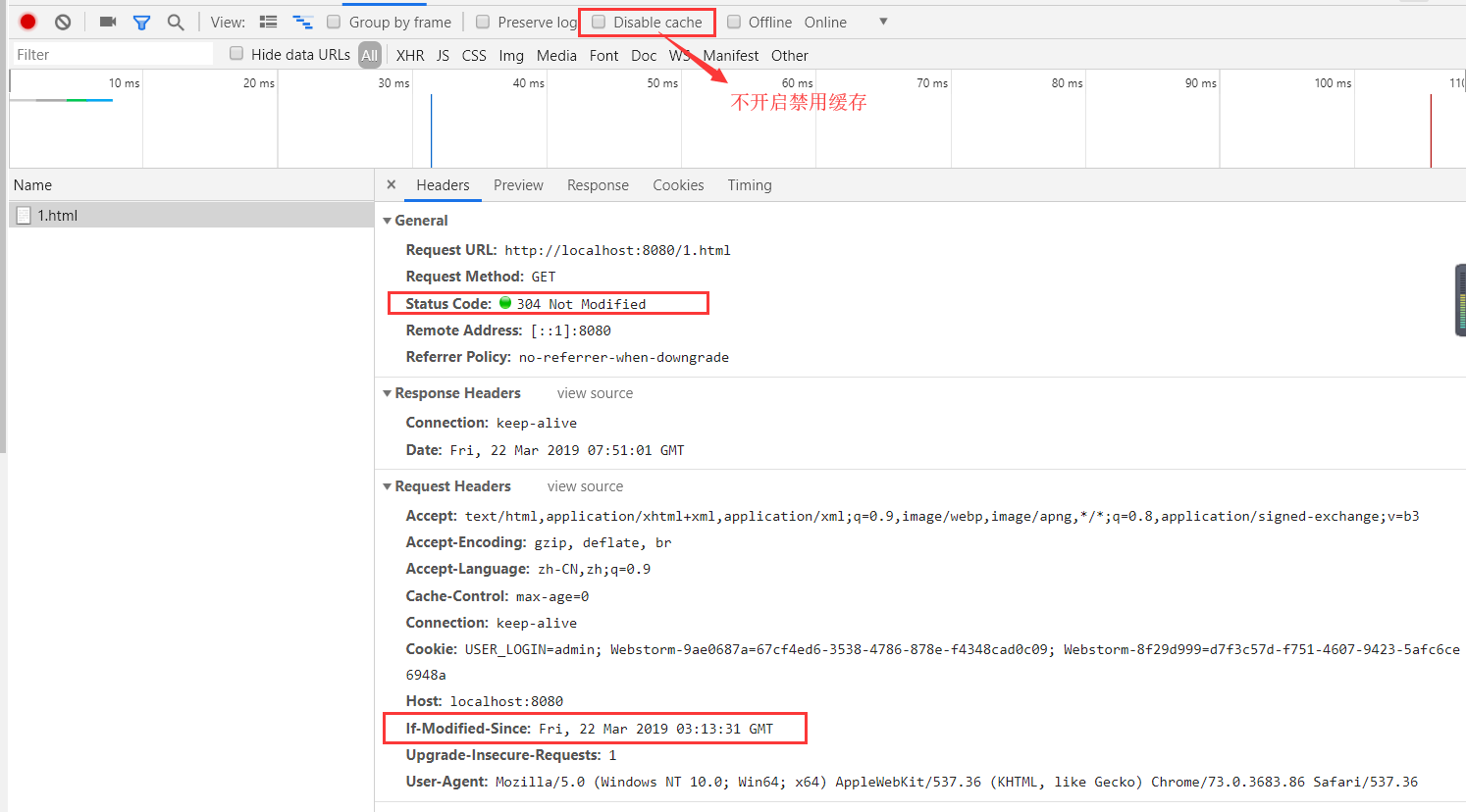
第二次请求,响应状态码304,浏览器有缓存
请求头带了if-modified-since标记该资源文件的最后一次修改时间,通过该标记去告诉服务器我本地有这个文件及这个文件最后一次修改时间,服务器收到请求通过if-modified-since标记的时间和服务器上该文件的时间进行比较,如果服务器的文件等于if-modified-since的时间,说明该资源文件没有被修改过,浏览器决定从不从缓存中取出
缓存策略
服务器设置响应头cache-control和expires
多进程
主进程负责派生子进程,子进程负责干活
特点
普通程序不能“创建”进程,只有系统进程才能创建进程;只有主进程能分裂
进程是分裂出来
分裂出来的两个进程执行的是同一套代码
父子进程之间可以共享”句柄”(如:8080端口)
进程分裂实现
通过cluster.isMaster判断是否是主进程,如果是主进程则cluster.fork()分裂子进程
1 | const http=require('http'); |
1 | 主进程 |
进程调度
主进程通过系统的CPU核数分裂了8个子进程,浏览器发起请求的时候只有一个子进程 26956干活
多个进程同时存在时,进程的调度原则是第一个进程满了才开启第二个进程,前面两个进程满了才开启第三个进程,这样做的原因是因为进程调度即进程切换是需要花费开销的
坑
主进程能否分裂100个进程,有必要么
可以分裂100个进程,但是没有必要,进程调度需要花费开销,况且进程的实际工作计算能力需要根据计算机本身硬件的限制
NodeJS使用MySQL
连接
一条连接
1 | let db=mysql.createConnection({host: 'localhost', user: 'root', password: '', port: 3309, database: '20180127'}); |
连接池获取连接
1 | //连接池 |
查询
1 | const mysql=require('mysql'); |
用户登录注册
数据库结构(数据字典)
接口格式(接口文档)
1 | 注册: |
1 | 登陆: |
代码实现
前台
1 |
|
后台
1 | const http=require('http'); |

